
I recently got acquainted with eBPF as the enabling technology for PLUMgrid’s distributed, programmable data-plane. While working on the product, perhaps due to my academic mindset, my mind got piqued by this technology described here as the “In-kernel Universal Virtual Machine”.
This led me further explore the history for eBPF and its parent Linux Foundation project IO Visor, resulting in these set of slides [link], which I used to deliver talks at universities, labs, and conferences. I communicated the technology at a high level as well, along with the efforts to make it more accessible by the IO Visor Project (important since, as Brenden Gregg described, raw eBPF programming as “brutal”). While other people have already explained eBPF and IO Visor earlier (BPF Internals I, BPF Internals II, and IO Visor Challenges Open vSwitch) , I wanted to talk here about possible research directions and the wide scope for this exciting technology.
Before I go into these areas, however, a short primer on eBPF is essential for completeness.
A brief history of Packet Filters
So let’s start with eBPF’s ancestor — the Berkeley Packet Filter (BPF). Essentially built to enable line rate monitoring of packet, BPF allows description of a simple filter inside the kernel that lets through (to userspace) only those packets that meet its criteria. This is the technology used by tcpdump (and its derivatives like wireshark and other tools using libpcap). Let’s look at an example (taken from this Cloudflare blog):
$ sudo tcpdump -p -ni eth0 “ip and udp”
with this program, tcpdump will sniff through all traffic at the eth0 interface and return UDP packets only. Adding a -d flag to the above commands actually does something interesting:
(000) ldh [12]
(001) jeq #0x800 jt 2 jf 5
(002) ldb [23]
(003) jeq #0x11 jt 4 jf 5
(004) ret #65535
(005) ret #0
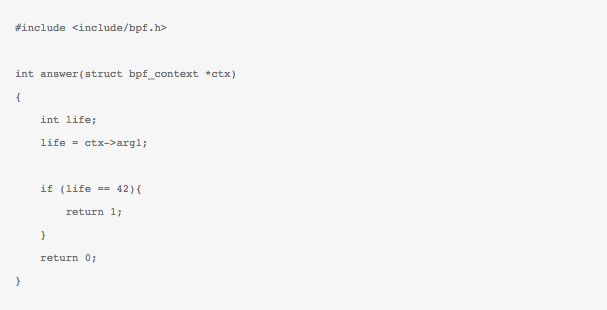
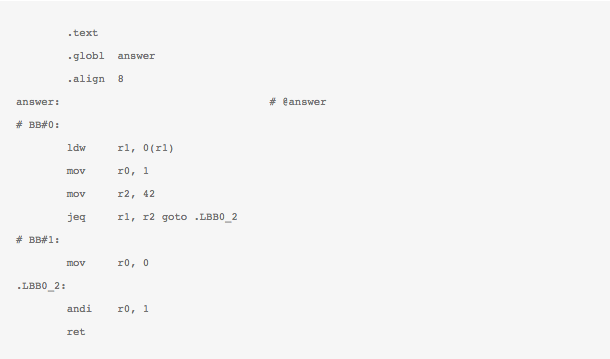
The above, recognizable as an assembly program for an ISA, shows a basic implementation of the filter as a bytecode that assumes a received packet resides at memory location [0] and then uses offset of Ethertype field and Protocol field, to drop packet the packet if UDP packet is not detected, by indicating a 0 (zero) return value.
This above code represents a bytecode for the BPF “psuedo-machine” architecture that is the underpinning of BPF. Thus what BPF provides is a simple machine architecture, sufficient to build packet filtering logic. Most of BPF safety guarantees arise from the very limited set of instructions allowed by the pseudo machine architecture, with a basic verifier to prevent loops was also exercise before the code is inserted inside the kernel. The in-kernel BPF is represented by an interpreter to allow the filter to be executed on every packet. For more details refer to this excellent blog post by Sukarma (link).
Extending BPF
Now this basic abstraction has been in the Linux kernel for nearly two decades, but recently got an upgrade with eBPF (e for extended) that has made BPF more than just a packet filter.
The main motivation behind eBPF was to extend the capabilities of BPF pseudo-machine to become more powerful and expressive, all the while providing the stability guarantees that ensured its existence in the kernel in the first place. This is a tough balancing act; on one hand making the BPF machine architecture more powerful means more machine instructions, more registers, bigger stack and 64 bit instructions. On the other hand — in line with the “with great power comes great responsibility” adage — the verification of the new bytecode also becomes significantly more challenging.
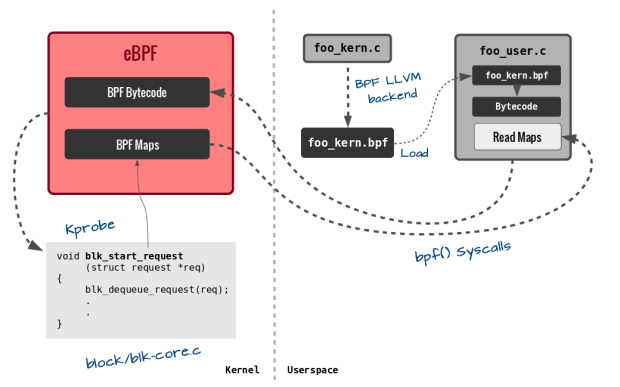
This challenge was taken up and delivered in the form of eBPF patch to the Linux kernel “filter”, with a new bpf syscall added from kernel 3.18. While the details of this new patch can be found at various different locations, including the presentation I have been giving, I will only briefly address the exciting new features and what they enable.
- Souped up machine architecture: eBPF makes the instruction set 64 bit and significantly expands its supported instruction count. Think of this like upgrading to a new Intel core architecture and the benefit in efficiency and capability therein. Another important consideration was to make the new architecture similar to x86-64, and ARM-64 architecture, thus allowing ease in writing a JIT compiler for eBPF bytecode.
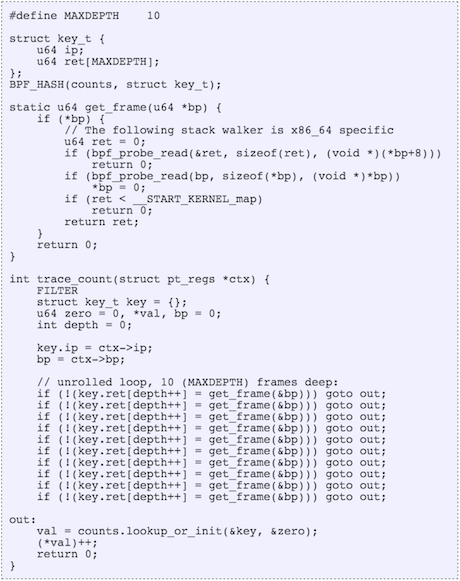
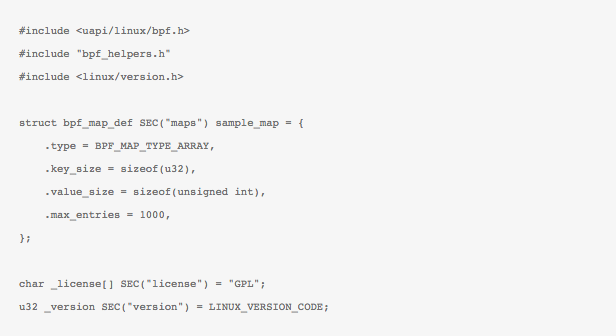
- Support for maps: This new feature allows storage of values between eBPF code execution. Notice that previously BPF programs were only run in isolation, with no-recall. The new map feature is crucially important as it allows the retention of state between every execution of eBPF code (full recall), thus allowing implementing a state-machine based on events triggering an eBPF function.
- Helper functions: Helper functions are akin to having a library that allows eBPF programs — restricted to the confines of the isolated/virtualized pseudo-machine of BPF — to access resources (like the above mentioned maps) in an approved, kernel-safe way. This allows for increasing eBPF capabilities by offloading some functions, like requesting pseudo-numbers or recalculating checksum, to programs outside the eBPF code.
- Tail-calls: As we noted earlier, pre-eBPF, programs would execute in isolation and had no (direct) control to trigger another filter/program. With the tail-call feature, an eBPF program can control the next eBPF program to execute. This ability allows a (sort-of) get-out-of-jail card from the per eBPF program restriction of 4096 instructions; more importantly it allows the ability to stitch containerized kernel code together — hence enabling micro-services inside kernel.
There are lots of details about the internals of eBPF program types, where they can be hooked, and the type of context they work with all over the interwebs (links at the end of this blog). We will skip this to focus next on what are the various different things people are already doing, and some “out there ideas” that can get people to start thinking in a different direction.
Before we go, note that most of the complexity of pushing code into kernel and then using helper-functions and tail-calls is being progressively reduced under the IO Visor Project’s github repository. This includes the ability to build code and manage maps through a python front-end (bcc) and a persistent file system in the form of bpf-fuse.
…. ask what eBPF can do for you?
So now that we understand the basics of the eBPF ecosystem, we discuss a few opportunities arising from having a programmable engine inside the kernel. Some of the ideas I will be throwing out there are already possible or being used, while others require some modifications to the eBPF ecosystem (by e.g., increasing the type of maps and helper functions) — something a creative developer can upstream into the Linux kernel (not easy, I know!).
Security
While BPF was originally meant to help in packet-filtering, the seccomp patch allowed for mechanism to trap system calls and possibly block them, thereby limiting the number of calls accessible to an application.
With eBPF ability to have shared maps across instances, we can do dynamic taint analysis which has a minimal overhead. This will increase ability to track and stop malware and security breaches.
Similarly, with the ability to keep state, it will be trivial to implement stateful packet filtering. With eBPF, each application can also build their own filtering mechanism — thus web servers can post intelligent DDoS rejection programs, that block traffic at the kernel without disrupting the application thread, and can be configured through maps. These DDoS signatures can be generated using more involved DDoS detection algorithm present in the user-space.
Tracing
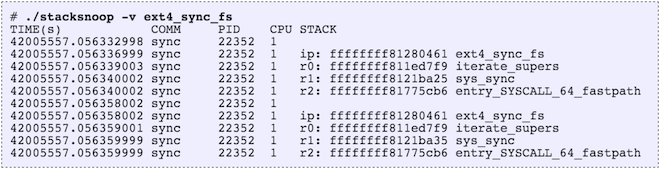
The introduction of eBPF has ignited significant interest in the tracing community. While I could describe several uses, the following blogs by Brenden Gregg (hist, off_cpu,uprobes), provide greater detail and convey the potential quite well.
Briefly, the ability to monitor kernel and user events (through kprobe and uprobe), then keep statistics in maps that can be polled from the user space provide the key differentiation from other tracing tools. These are useful as they enable the “Goldilocks effect” — the right amount of insight without perturbing the monitored system metric significantly.
Networking
Since eBPF programs can hook into different places of the networking stack, we can now program networking logic that can look at the entire payload, read any protocol header type, and keep state to implement any protocol machine. These capabilities allow for building a programmable data-plane inside commodity machines.
Another key feature of eBPF, the ability to call other programs, allows us to connect eBPF programs and pass packets between them. This in essence allows us to build an orchestration system that can connect eBPF program and implement a chain of network functions. Thus third party vendors can build best-of-breed network elements, which can then be stitched together using the tail-call capability in eBPF. This independence guarantees greatest possible flexibility for users planning to build a powerful and cost-effective data-plane. The fact that PLUMgrid builds its entire ONS product line on top of this core functionality is a testament to its potential in this area as well.
IoT devices and development
How can a tech-blog be complete without throwing in the IoT buzz word? Well, it seems to me there is an interesting — albeit futuristic — application of eBPF in the IoT space. First, let me postulate that widespread IoT acceptance is hampered by the current approach of using specialized, energy efficient operating systems like TinyOS, Contiki, RIOT. If instead we have the ability to use tools familiar to typical developers (within a standard Linux environment), the integration and development of solutions will be accelerated.
With the above premise, it is interesting to think of building an event-based microkernel like OS inside the monolithic Linux Kernel. This can happen if it becomes feasible (or safe) to trap (even if a subset of) I/O interrupts and invoke an energy-aware scheduler to appropriate set state for both radio and processor on these devices. The event-driven approach to building an IoT application is perfectly inline with current best-practices, inasmuch that the above IoT specific OS use this approach for optimizing performance. At the same time, before deployment, and for debugging or even upgrading the IoT application, normal Linux tools will be available for developers and users alike.
Mobile Apps
Android will soon have eBPF functionality — when it does, the possibility of pushing functionality to monitor per application usage inside the kernel can make for some very interesting monitoring apps. We can implement several of the applications above, but with the additional benefits of having lower impact on the battery life.
Conclusion
While I have tried to convey a summary of eBPFs capability and its possible use-cases, community efforts driven by the IOVisor project continue to expand the horizon. IO Visor argues for an abstract model of an IO Module along with a mechanism to connect between such modules and other system components. These modules, described as an eBPF program, can as one instantiation be run within the Linux kernel, but can also be extrapolated to other implementations using offloads. Having the same interface, an eBPF program and its capabilities, will allow users to design and define IO interactions in an implementation independent way, with the actual implementation optimized for a particular use case e.g. NFV and data-plane acceleration.
If you are interested in IO Visor, join the IO Visor developer mailing, follow @iovisor twitter group and find out more about the project. See you there.
Useful Links
https://github.com/iovisor/bpf-docs
http://lwn.net/Articles/603984/
http://lwn.net/Articles/603983/
https://lwn.net/Articles/625224/
https://www.kernel.org/doc/Documentation/networking/filter.txt
http://man7.org/linux/man-pages/man2/bpf.2.html
https://videos.cdn.redhat.com/summit2015/presentations/13737_an-overview-of-linux-networking-subsystem-extended-bpf.pdf
https://github.com/torvalds/linux/tree/master/samples/bpf
http://lxr.free-electrons.com/source/net/sched/cls_bpf.c
—
About the author of this post
 Affan Ahmed Syed
Affan Ahmed Syed
Director Engineering at PLUMgrid Inc.
LinkedIn | Twitter: @aintiha

 Brendan Gregg
Brendan Gregg Brenden is an Architect in the CTO Office at PLUMgrid where he works on designing software networking infrastructures and analytics tools for Linux. Specifically, he is a key contributor to the IO Visor project, a Linux Foundation Collaborative Project geared towards creating a platform for open programmable data planes for modern IO and networking applications.
Brenden is an Architect in the CTO Office at PLUMgrid where he works on designing software networking infrastructures and analytics tools for Linux. Specifically, he is a key contributor to the IO Visor project, a Linux Foundation Collaborative Project geared towards creating a platform for open programmable data planes for modern IO and networking applications.




 Suchakra Sharma
Suchakra Sharma






 Pere Monclus, CTO and Co Founder of PLUMgrid
Pere Monclus, CTO and Co Founder of PLUMgrid